The Radix Heap
The Radix Heap is a priority queue that has better caching behavior than the well-known binary heap, but also two restrictions: (a) that all the keys in the heap are integers and (b) that you can never insert a new item that is smaller than all the other items currently in the heap.
These restrictions are not that severe. The Radix Heap still works in many algorithms that use heaps as a subroutine: Dijkstra’s shortest-path algorithm, Prim’s minimum spanning tree algorithm, various sweepline algorithms in computational geometry.
Here is how it works. If we assume that the keys are 32 bit integers,
the radix heap will have 33 buckets, each one containing a list of
items. We also maintain one global value last_deleted, which is
initially MIN_INT and otherwise contains the last value extracted
from the queue.
The invariant is this:
The items in bucket
$k$ differ fromlast_deletedin bit$k - 1$ , but not in bit$k$ or higher. The items in bucket 0 are equal tolast_deleted.
For example, if we compare an item from bucket 10 to last_deleted,
we will find that bits 31–10 are equal, bit 9 is different, and bits
8–0 may or may not be different.
Here is an example of a radix heap where the last extracted value was 7:
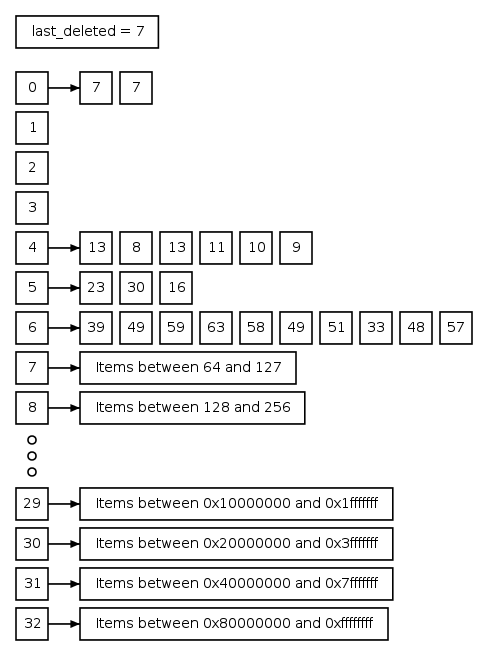
As an example, consider the item 13 in bucket 4. The bit pattern of 7
is 0111 and the bit pattern of 13 is 1101, so the highest bit that is
different is bit number 3. Therefore the item 13 belongs in bucket
Operations
When a new item is inserted, it has to be added to the correct
bucket. How can we compute the bucket number? We have to find the
highest bit where the new item differs from last_deleted. This is
easily done by XORing them together and then finding the highest bit
in the result. Adding one then gives the bucket number:
bucket_no = highest_bit (new_element XOR last_deleted) + 1
where highest_bit(x) is a function that returns the highest set bit
of x, or x is 0.
Inserting the item clearly preserves the invariant because the new
item will be in the correct bucket, and last_deleted didn’t change,
so all the existing items are still in the right place.
Extracting the minimum involves first finding the minimal item by
walking the lowest-numbered non-empty bucket and finding the minimal
item in that bucket. Then that item is deleted and last_deleted is
updated. Then the bucket is walked again and all the items are
redistributed into new buckets according to the new last_deleted
item.
The extracted item will be the minimal one in the data structure
because we picked the minimal item in the redistributed bucket, and
all the buckets with lower numbers are empty. And if there were a
smaller item in one of the buckets with higher numbers, it would be
differing from last_deleted in one of the more significant bits, say
bit last_deleted in bit last_deleted, which it can’t be because
of restriction (b) mentioned in the introduction. Note that this
argument also works for two-complement signed integers.
We have to be sure this doesn’t violate the invariant. First note that
all the items that are being redistributed will satisfy the invariant
because they are simply being inserted. The items in a bucket with a
higher number last_deleted in
the last_deleted, because if it
weren’t, the new last_deleted would itself have belonged in bucket
In the example above, if we extract the two ‘7’s from bucket 0 and the ‘8’ from bucket 4, the new heap will look like this:

Notice that bucket 4, where the ‘8’ came from, is now empty.
Performance
Inserting into the radix heap takes constant time because all we have
to do is add the new item to a list. Determining the highest set bit
can be done in constant time with an instruction such as bsr.
The performance of extraction is dominated by the redistribution of
items. When a bucket is redistributed, it ends up being empty. To see
why, remember that all the items are different from last_deleted in
the last_deleted comes from bucket
last_deleted in the
Now consider the life-cycle of a single element. In the worst case it starts out being added to bucket 31 and every time it is redistributed, it moves to a lower-numbered bucket. When it reaches bucket 0, it will be next in line for extraction. It follows that the maximum number of redistributions that an element can experience is 31.
Since a redistribution takes constant time per element distributed,
and since an element will only be redistributed
Caching performance
Some descriptions of the radix heap recommend implementing the buckets
as doubly linked lists, but that would be a mistake because linked
lists have terrible cache locality. It is better to implement them as
dynamically growing arrays. If you do that, the top of the buckets
will tend to be hot which means the per-item number of cache misses
during redistribution of a bucket will tend to be
In a regular binary heap, both insertion and extraction require
In other words, if